1、[CV] Dual PatchNorm
2、[LG] Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment
3、[CV] Factor Fields: A Unified Framework for Neural Fields and Beyond
4、[CV] Dreamix: Video Diffusion Models are General Video Editors
5、[CL] Multimodal Chain-of-Thought Reasoning in Language Models
[CL] Accelerating Large Language Model Decoding with Speculative Sampling
[LG] Mnemosyne: Learning to Train Transformers with Transformers
[CV] Patch Gradient Descent: Training Neural Networks on Very Large Images
[LG] Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data
摘要:Dual PatchNorm、基于语言量化自编码器的无监督文本图像对齐、用因子场统一建模与信号表示神经场、基于视频扩散模型的通用视频编辑器、语言模型的多模态思想链推理、用投机采样加速大型语言模型解码、基于Transformer的Mnemosyne优化器、用块梯度下降在非常大的图像上训练神经网络、通过探索和利用辅助数据来改进少样本的泛化
1、[CV] Dual PatchNorm
M Kumar, M Dehghani, N Houlsby
[Google Research]
Dual PatchNorm
要点:
-
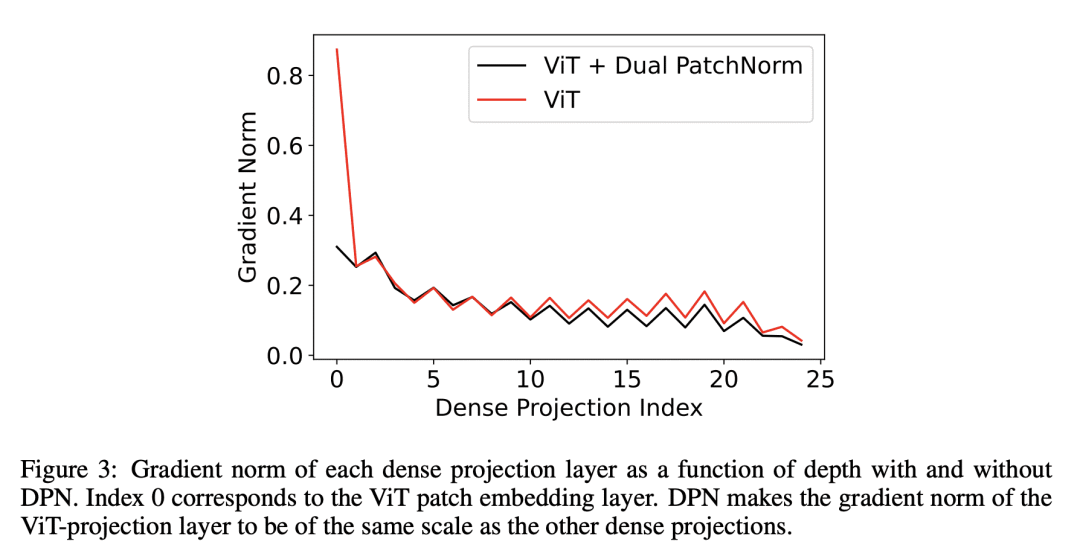
提出 Dual PatchNorm,用于视觉 Transformer 的一种新方法,由图块嵌入层前后的两个Layer Normalization层组成; -
证明 Dual PatchNorm 优于对 Transformer 块中其他 LayerNorm 放置策略的遍历搜索结果; -
观察到在 ViT 投影层前后放置额外的 LayerNorm(Dual PatchNorm)改善了微调好的ViT基线。
一句话总结:
Dual PatchNorm 方法由图块嵌入层前后的两个 Layer Normalization 层组成,在 Vision Transformer 中优于其他 LayerNorm 放置策略,并改善了经过良好微调后的ViT基线。
摘要:
本文提出 Dual PatchNorm:在视觉 Transformer 的图块嵌入层之前和之后有两个 Layer Normalization 层(LayerNorm)。证明了 Dual PatchNorm 优于在 Transformer 块本身遍历搜索替代 LayerNorm 放置策略的结果。在实验中纳入这种微不足道的修改,往往会导致比经过良好调整的视觉 Transformer 更高的精度,而且不会有任何损失。
We propose Dual PatchNorm: two Layer Normalization layers (LayerNorms), before and after the patch embedding layer in Vision Transformers. We demonstrate that Dual PatchNorm outperforms the result of exhaustive search for alternative LayerNorm placement strategies in the Transformer block itself. In our experiments, incorporating this trivial modification, often leads to improved accuracy over well-tuned Vision Transformers and never hurts.
https://arxiv.org/abs/2302.01327



2、[LG] Language Quantized AutoEncoders: Towards Unsupervised Text-Image Alignment
H Liu, W Yan, P Abbeel
[UC Berkeley]
语言量化自编码器:无监督文本图像对齐研究
要点:
-
提出了 LQAE,一种用预训练语言模型将图像与未对齐的文本-图像对对齐的方法; -
允许通过标准提示,用大型语言模型进行少少样本图像的分类,而不需要进行任何微调; -
允许使用BERT进行图像线性分类。
一句话总结:
LQAE 用预训练语言模型(如BERT)将图像与没有文本-图像对的文本 token 对齐,实现了用大型语言模型进行少样本图像分类和用BERT文本特征对图像进行线性分类。
摘要:
最近在扩展大型语言模型方面的进展,显示了在广泛的基于文本的任务中进行少样本学习的惊人能力。然而,一个关键的限制是,这些语言模型从根本上缺乏视觉感知——这是扩展这些模型以便能与现实世界互动和解决视觉任务所需要的关键属性,例如在视觉问答和机器人方面。之前的工作主要是通过预训练和/或在策划的图像-文本数据集上进行微调,将图像与文本连接起来,这可能是一个昂贵的过程。为解决这一局限性,本文提出一种简单而有效的方法,语言量化自编码器(LQAE),这是VQ-VAE的一种修改,通过用预训练语言模型(如BERT、RoBERTa),以无监督方式学习文本-图像数据对齐。其主要想法是通过用预训练的语言码本直接量化图像嵌入,将图像编码为文本token的序列。在BERT模型之后应用随机掩码,让解码器从 BERT 预测的文本 token 嵌入中重建原始图像。这样,LQAE 学会了用相似的文本 token 簇来表示相似的图像,从而在不使用对齐文本-图像对的情况下将这两种模式对齐。这使得用大型语言模型(如GPT-3)进行少样本图像分类,以及基于BERT文本特征的图像线性分类成为可能。本文工作是第一项通过利用预训练的语言模型的力量将未对齐的图像用于多模态任务的工作。
Recent progress in scaling up large language models has shown impressive capabilities in performing few-shot learning across a wide range of text-based tasks. However, a key limitation is that these language models fundamentally lack visual perception – a crucial attribute needed to extend these models to be able to interact with the real world and solve vision tasks, such as in visual-question answering and robotics. Prior works have largely connected image to text through pretraining and/or fine-tuning on curated image-text datasets, which can be a costly and expensive process. In order to resolve this limitation, we propose a simple yet effective approach called Language-Quantized AutoEncoder (LQAE), a modification of VQ-VAE that learns to align text-image data in an unsupervised manner by leveraging pretrained language models (e.g., BERT, RoBERTa). Our main idea is to encode image as sequences of text tokens by directly quantizing image embeddings using a pretrained language codebook. We then apply random masking followed by a BERT model, and have the decoder reconstruct the original image from BERT predicted text token embeddings. By doing so, LQAE learns to represent similar images with similar clusters of text tokens, thereby aligning these two modalities without the use of aligned text-image pairs. This enables few-shot image classification with large language models (e.g., GPT-3) as well as linear classification of images based on BERT text features. To the best of our knowledge, our work is the first work that uses unaligned images for multimodal tasks by leveraging the power of pretrained language models.
https://arxiv.org/abs/2302.00902



3、[CV] Factor Fields: A Unified Framework for Neural Fields and Beyond
A Chen, Z Xu, X Wei, S Tang, H Su, A Geiger
[ETH Zurich & Adobe Research & University of California, San Diego & University of Tubingen]
因子场:用于建模和信号表示的神经场统一框架
要点:
-
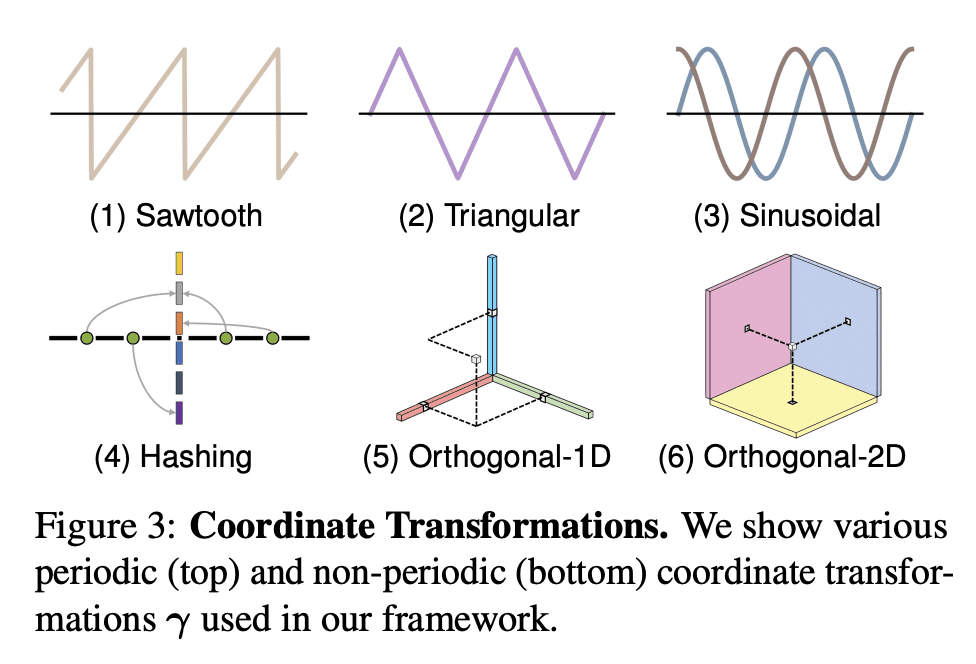
提出因子场,一种用于建模和信号表示的新框架,将信号分解为因子的乘积; -
提出CoBaFa,因子场族的一种新的表示方法,将信号分解为系数和基因子; -
对 CoBaFa 在 2D 图像回归、3D SDF 重建和辐射场重建任务上进行了广泛的评估,并证明其性能比之前的方法有所提高。
一句话总结:
提出因子场,一种用于建模和信号表示的统一框架,推广了之前的神经场表征,使新模型具有更好的准确性、效率和紧凑性。
摘要:
本文提出因子场,一种用于建模和信号表示的新框架。因子场将信号分解为因子的乘积,其中每个因子都由在坐标转换的输入信号上操作的神经场或规则场表示。这种分解产生了一个统一的框架,推广了最近的几种信号表示方法,包括 NeRF、PlenOxels、EG3D、Instant-NGP 和 TensoRF。此外,该框架允许创建强大的新信号表示法,如本文提出的系数基数分解(CoBaFa)。正如实验所证明的那样,CoBaFa 在神经信号表征的三个关键目标方面比之前的快速重建方法有所改进:近似质量、紧凑性和效率。通过实验证明了与之前的快速重建方法相比,所提出表示在 2D 图像回归任务中实现了更好的图像近似质量,在重建 3D 有符号距离场时实现了更高的几何质量,在辐射场重建任务中实现了更高的紧凑性。CoBaFa表示通过在训练过程中分享不同信号的基来实现泛化,从而实现泛化任务,如用稀疏的观测值进行图像回归和少样本辐射场重建。
We present Factor Fields, a novel framework for modeling and representing signals. Factor Fields decomposes a signal into a product of factors, each of which is represented by a neural or regular field representation operating on a coordinate transformed input signal. We show that this decomposition yields a unified framework that generalizes several recent signal representations including NeRF, PlenOxels, EG3D, Instant-NGP, and TensoRF. Moreover, the framework allows for the creation of powerful new signal representations, such as the Coefficient-Basis Factorization (CoBaFa) which we propose in this paper. As evidenced by our experiments, CoBaFa leads to improvements over previous fast reconstruction methods in terms of the three critical goals in neural signal representation: approximation quality, compactness and efficiency. Experimentally, we demonstrate that our representation achieves better image approximation quality on 2D image regression tasks, higher geometric quality when reconstructing 3D signed distance fields and higher compactness for radiance field reconstruction tasks compared to previous fast reconstruction methods. Besides, our CoBaFa representation enables generalization by sharing the basis across signals during training, enabling generalization tasks such as image regression with sparse observations and few-shot radiance field reconstruction.
https://arxiv.org/abs/2302.01226



4、[CV] Dreamix: Video Diffusion Models are General Video Editors
E Molad, E Horwitz, D Valevski, A R Acha, Y Matias, Y Pritch, Y Leviathan, Y Hoshen
[Google Research]
Dreamix: 基于视频扩散模型的通用视频编辑器
要点:
-
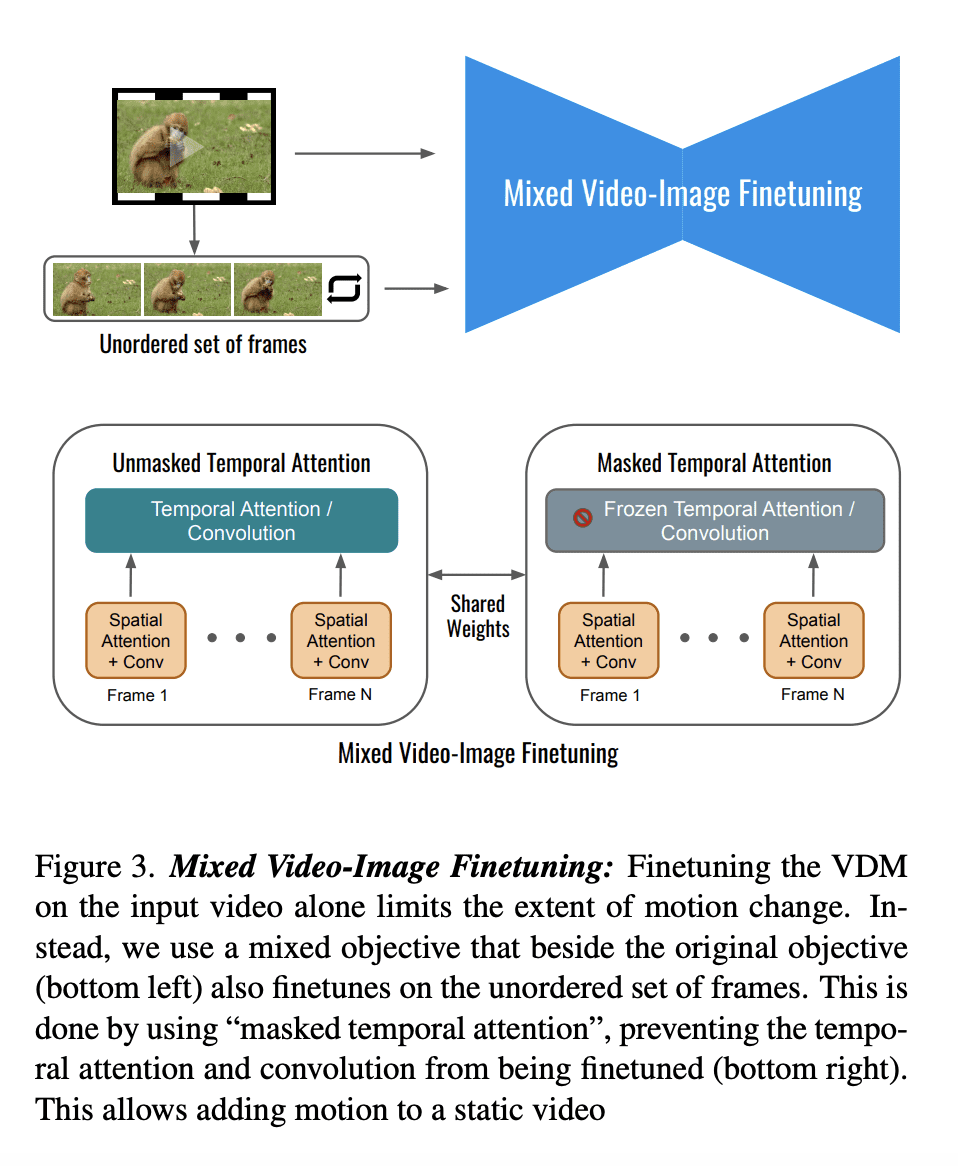
提出第一个基于扩散的方法,用于一般视频的基于文本的运动和外观编辑; -
使用混合微调模型来提高运动编辑的质量; -
通过将简单的图像处理操作与视频编辑方法相结合,为文字引导的图像动画提供了新的框架。
一句话总结:
提出第一个基于扩散的文本视频编辑方法,提高了运动编辑质量,为文本引导的图像动画提供了框架,并演示了使用新型微调方法的主题驱动视频生成。
摘要:
文本驱动的图像和视频扩散模型,最近实现了前所未有的生成真实性。虽然扩散模型已经成功地应用于图像编辑,但很少有作品能在视频编辑中做到这一点。本文提出第一个基于扩散的方法,能够对一般视频进行基于文本的运动和外观编辑。该方法使用视频扩散模型,在推理时将原始视频中的低分辨率时空信息与新的高分辨率信息结合起来,这些信息是由它合成的,与指导性文本提示一致。由于获得原始视频的高保真度需要保留一些高分辨率的信息,在原始视频上增加了一个模型微调的初步阶段,大大提升了保真度。本文提出通过一个新的、混合的目标来提高运动的可编辑性,这个目标是通过完全的基于时间注意力掩码的时间注意力来联合微调。本文进一步介绍了一个新的图像动画框架。首先通过简单的图像处理操作,如复制和透视几何投影,将图像转化为粗略的视频,然后使用所提出的通用视频编辑器来制作动画。作为进一步的应用,可以将该方法用于主题驱动的视频生成。广泛的定性和数值实验展示了所提出方法显著的编辑能力,并确立了它与基线方法相比的卓越性能。
Text-driven image and video diffusion models have recently achieved unprecedented generation realism. While diffusion models have been successfully applied for image editing, very few works have done so for video editing. We present the first diffusion-based method that is able to perform text-based motion and appearance editing of general videos. Our approach uses a video diffusion model to combine, at inference time, the low-resolution spatio-temporal information from the original video with new, high resolution information that it synthesized to align with the guiding text prompt. As obtaining high-fidelity to the original video requires retaining some of its high-resolution information, we add a preliminary stage of finetuning the model on the original video, significantly boosting fidelity. We propose to improve motion editability by a new, mixed objective that jointly finetunes with full temporal attention and with temporal attention masking. We further introduce a new framework for image animation. We first transform the image into a coarse video by simple image processing operations such as replication and perspective geometric projections, and then use our general video editor to animate it. As a further application, we can use our method for subject-driven video generation. Extensive qualitative and numerical experiments showcase the remarkable editing ability of our method and establish its superior performance compared to baseline methods.
https://arxiv.org/abs/2302.01329



5、[CL] Multimodal Chain-of-Thought Reasoning in Language Models
Z Zhang, A Zhang, M Li, H Zhao, G Karypis, A Smola
[Shanghai Jiao Tong University & Amazon Web Services]
语言模型的多模态思想链推理
要点:
-
多模态思维链推理问题的正式研究; -
提出了一种两阶段框架,用于微调语言模型以纳入视觉信号; -
在ScienceQA基准上取得新的最先进性能。
一句话总结:
提出一种新方法——多模态CoT,通过对基于视觉和语言特征的小型语言模型进行微调,在多模态中进行思维链(CoT)推理,从而在ScienceQA基准上获得最先进的性能。
摘要:
大型语言模型(LLM)通过利用思维链(CoT)提示,生成中间推理链作为推断答案的依据,在复杂推理上表现出令人印象深刻的性能。然而,现有的CoT研究大多是隔离在LLM语言模态下,LLM很难部署。为了在多模态中引出CoT推理,一个可能的解决方案是通过融合视觉和语言特征来微调小的语言模型来进行CoT推理。关键的挑战是,这些语言模型往往会产生幻觉推理链,误导答案推理。为了减轻这种错误的影响,本文提出多模态CoT,在一个解耦的训练框架中加入了视觉特征。该框架将原理生成和答案推理分成两个阶段。通过将视觉特征纳入这两个阶段,该模型能生成有助于答案推理的有效理由。通过Multimodal-CoT,所提出模型在10亿个参数下比以前最先进的LLM(GPT-3.5)在ScienceQA基准上的表现高出16%(75.17%->91.68%),甚至超过了人类的表现。
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies are mostly isolated in the language modality with LLMs, where LLMs are hard to deploy. To elicit CoT reasoning in multimodality, a possible solution is to fine-tune small language models by fusing the vision and language features to perform CoT reasoning. The key challenge is that those language models tend to generate hallucinated reasoning chains that mislead the answer inference. To mitigate the effect of such mistakes, we propose Multimodal-CoT that incorporates vision features in a decoupled training framework. The framework separates the rationale generation and answer inference into two stages. By incorporating the vision features in both stages, the model is able to generate effective rationales that contribute to answer inference. With Multimodal-CoT, our model under 1 billion parameters outperforms the previous state-of-the-art LLM (GPT-3.5) by 16% (75.17%->91.68%) on the ScienceQA benchmark and even surpasses human performance.
https://arxiv.org/abs/2302.00923



另外几篇值得关注的论文:
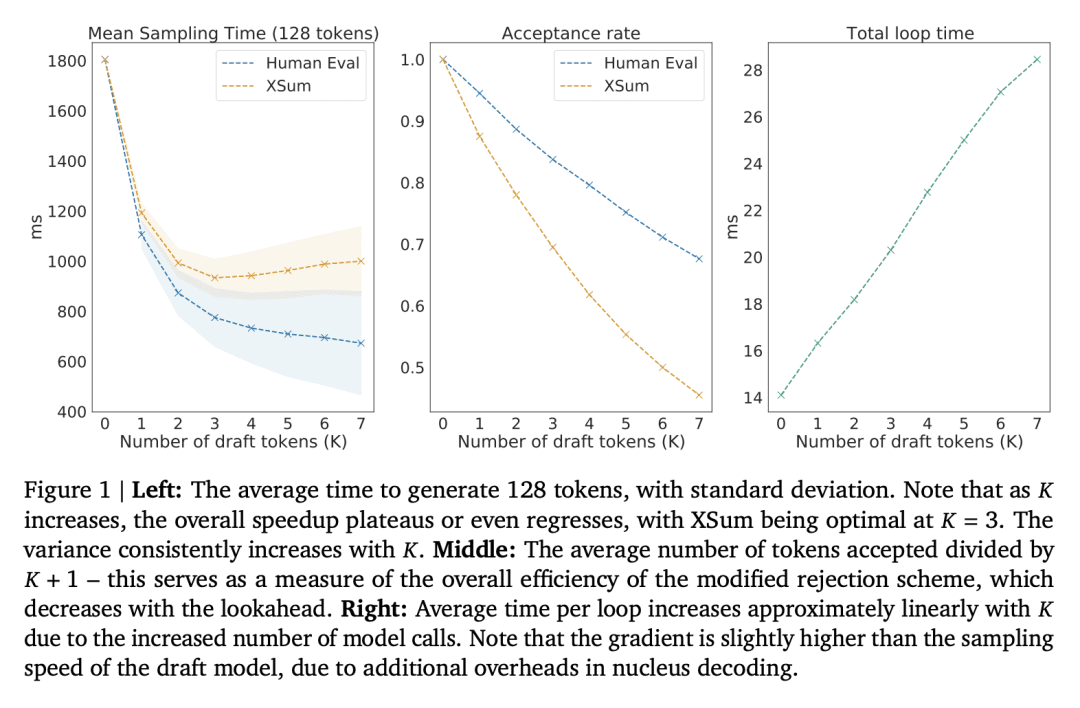
[CL] Accelerating Large Language Model Decoding with Speculative Sampling
C Chen, S Borgeaud, G Irving, J Lespiau, L Sifre, J Jumper
[DeepMind]
用投机采样加速大型语言模型解码
要点:
-
提出一种叫做投机采样的新算法,在不影响样本质量的情况下加快了 Transformer 解码的速度; -
从每个 Transformer 调用产生多个token,使用由草案模型产生的短连续的并行评分; -
采用修改过的拒绝采样方案被来保留目标模型在硬件数值中的分布。
一句话总结:
提出投机取样,一种通过从每个 Transformer 调用中生成多个令牌来加速 Transformer 解码的算法,在不影响采样质量或修改目标模型的情况下实现了2-2.5倍的速度。
We present speculative sampling, an algorithm for accelerating transformer decoding by enabling the generation of multiple tokens from each transformer call. Our algorithm relies on the observation that the latency of parallel scoring of short continuations, generated by a faster but less powerful draft model, is comparable to that of sampling a single token from the larger target model. This is combined with a novel modified rejection sampling scheme which preserves the distribution of the target model within hardware numerics. We benchmark speculative sampling with Chinchilla, a 70 billion parameter language model, achieving a 2-2.5x decoding speedup in a distributed setup, without compromising the sample quality or making modifications to the model itself.
https://arxiv.org/abs/2302.01318

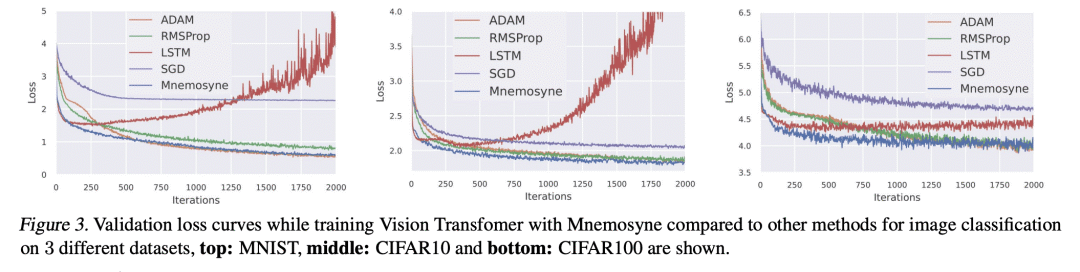
[LG] Mnemosyne: Learning to Train Transformers with Transformers
D Jain, K M Choromanski, S Singh, V Sindhwani, T Zhang, J Tan, A Dubey
[Google Robotics]
Mnemosyne: 用 Transformer 学习训练 Transformer
要点:
-
提出基于隐性低秩注意力Transformer Performer的Mnemosyne优化器; -
Mnemosyne可以学习训练整个神经网络架构,包括其他Transformer,而不需要特定任务的优化器调整; -
Mnemosyne比流行的LSTM优化器的通用性更好,可以成功地训练视觉Transformer(ViT),并可以在机器人应用中初始化优化器以实现更快的收敛。
一句话总结:
提出Mnemosyne,一种新的学习型优化器,使用Performer(隐性低秩注意力Transformer)来编码记忆单元,可学习训练整个神经网络架构,比流行的LSTM优化器具有更好的泛化能力。
Training complex machine learning (ML) architectures requires a compute and time consuming process of selecting the right optimizer and tuning its hyper-parameters. A new paradigm of learning optimizers from data has emerged as a better alternative to hand-designed ML optimizers. We propose Mnemosyne optimizer, that uses Performers: implicit low-rank attention Transformers. It can learn to train entire neural network architectures including other Transformers without any task-specific optimizer tuning. We show that Mnemosyne: (a) generalizes better than popular LSTM optimizer, (b) in particular can successfully train Vision Transformers (ViTs) while meta–trained on standard MLPs and (c) can initialize optimizers for faster convergence in Robotics applications. We believe that these results open the possibility of using Transformers to build foundational optimization models that can address the challenges of regular Transformer training. We complement our results with an extensive theoretical analysis of the compact associative memory used by Mnemosyne.
https://arxiv.org/abs/2302.01128



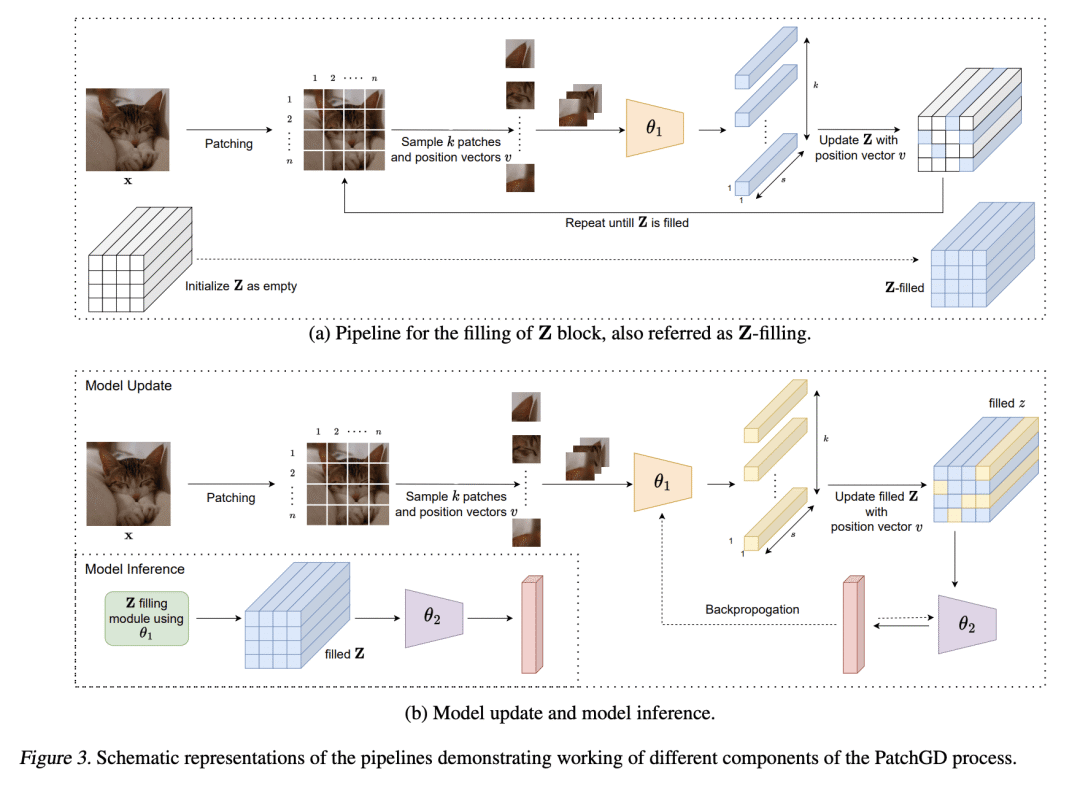
[CV] Patch Gradient Descent: Training Neural Networks on Very Large Images
D K. Gupta, G Mago, A Chavan, D K. Prasad
[Indian Institute of Technology & UiT The Arctic University of Norway]
块梯度下降(PatchGD): 在非常大的图像上训练神经网络
要点:
-
提出图块梯度下降(PatchGD),作为一种新策略,以端到端方式在非常大的图像上训练神经网络; -
PatchGD在小型GPU上的可扩展性,主要是因为它能处理给定图像的小块内容; -
由于其简单的设计,PatchGD与任何现有的CNN架构相兼容。
一句话总结:
提出 Patch Gradient Descent(PatchGD),一种新的CNN训练策略,能够以高效和可扩展的方式处理大型图像。
Traditional CNN models are trained and tested on relatively low resolution images (<300 px), and cannot be directly operated on large-scale images due to compute and memory constraints. We propose Patch Gradient Descent (PatchGD), an effective learning strategy that allows to train the existing CNN architectures on large-scale images in an end-to-end manner. PatchGD is based on the hypothesis that instead of performing gradient-based updates on an entire image at once, it should be possible to achieve a good solution by performing model updates on only small parts of the image at a time, ensuring that the majority of it is covered over the course of iterations. PatchGD thus extensively enjoys better memory and compute efficiency when training models on large scale images. PatchGD is thoroughly evaluated on two datasets – PANDA and UltraMNIST with ResNet50 and MobileNetV2 models under different memory constraints. Our evaluation clearly shows that PatchGD is much more stable and efficient than the standard gradient-descent method in handling large images, and especially when the compute memory is limited.
https://arxiv.org/abs/2301.13817



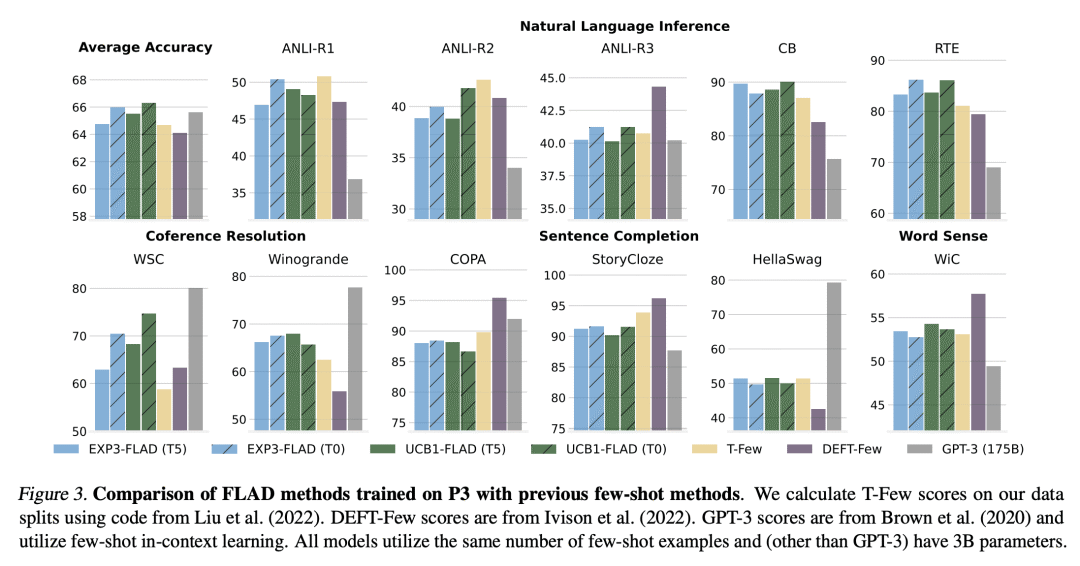
[LG] Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data
A Albalak, C Raffel, W Y Wang
[University of California, Santa Barbara & University of North Carolina]
通过探索和利用辅助数据来改进少样本的泛化
要点:
-
将FLAD与多臂老虎机设定联系起来,并关注探索-利用权衡; -
设计两种算法,EXP3-FLAD和UCB1-FLAD,使现有的MAB方法适应FLAD设置; -
经验验证了所提出方法改善了预训练语言模型的少样本性能,而单独的探索或利用会导致次优的性能。
一句话总结:
提出一种新的辅助数据少样本学习(FLAD)方法,将其与多臂老虎机设置相联系,并设计了平衡探索和利用的算法,带来了与基线相比性能的提高。
Few-shot learning involves learning an effective model from only a few labeled datapoints. The use of a small training set makes it difficult to avoid overfitting but also makes few-shot learning applicable to many important real-world settings. In this work, we focus on Few-shot Learning with Auxiliary Data (FLAD), a training paradigm that assumes access to auxiliary data during few-shot learning in hopes of improving generalization. Introducing auxiliary data during few-shot learning leads to essential design choices where hand-designed heuristics can lead to sub-optimal performance. In this work, we focus on automated sampling strategies for FLAD and relate them to the explore-exploit dilemma that is central in multi-armed bandit settings. Based on this connection we propose two algorithms — EXP3-FLAD and UCB1-FLAD — and compare them with methods that either explore or exploit, finding that the combination of exploration and exploitation is crucial. Using our proposed algorithms to train T5 yields a 9% absolute improvement over the explicitly multi-task pre-trained T0 model across 11 datasets.
https://arxiv.org/abs/2302.00674



















💕