1、[LG] Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier
2、[LG] Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
3、[LG] Conceptual SCAN: Learning With and About Rules
4、[LG] Fully Online Meta Learning
5、[LG] Offline Reinforcement Learning from Heteroskedastic Data Via Support Constraints
[RO] Open-World Object Manipulation using Pre-trained Vision-Language Models
[LG] Differentially Private Diffusion Models Generate Useful Synthetic Images
[CL] Interactive Text Generation
[LG] Understanding plasticity in neural networks
摘要:打破重放率限制的样本高效强化学习、二分类贝叶斯误差估计的直接方法、规则的学习与理解、全在线元学习、基于支持约束的异方差数据离线强化学习、基于预训练视觉-语言模型的开放世界对象操纵、基于差分隐私扩散模型生成有用的合成图像、交互式文本生成、理解神经网络的可塑性
1、[LG] Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier
P D’Oro, M Schwarzer, E Nikishin, P Bacon, M G Bellemare, A Courville
[Universite de Montreal & Google Brain]
打破重放率限制的样本高效强化学习
要点:
-
完全或部分重设智能体参数可改善重放率的扩展和采样效率; -
该方法大大改善了 Atari 100k 和 DeepMind Control Suite 基准的性能; -
在线数据收集对于实现有利的重放率扩展很有价值; -
发现与深度强化学习系统有关的新现象可以导向更有效算法的开发。
一句话总结:
重置智能体参数可以使深度强化学习算法有更好的重放率扩展和采样效率。
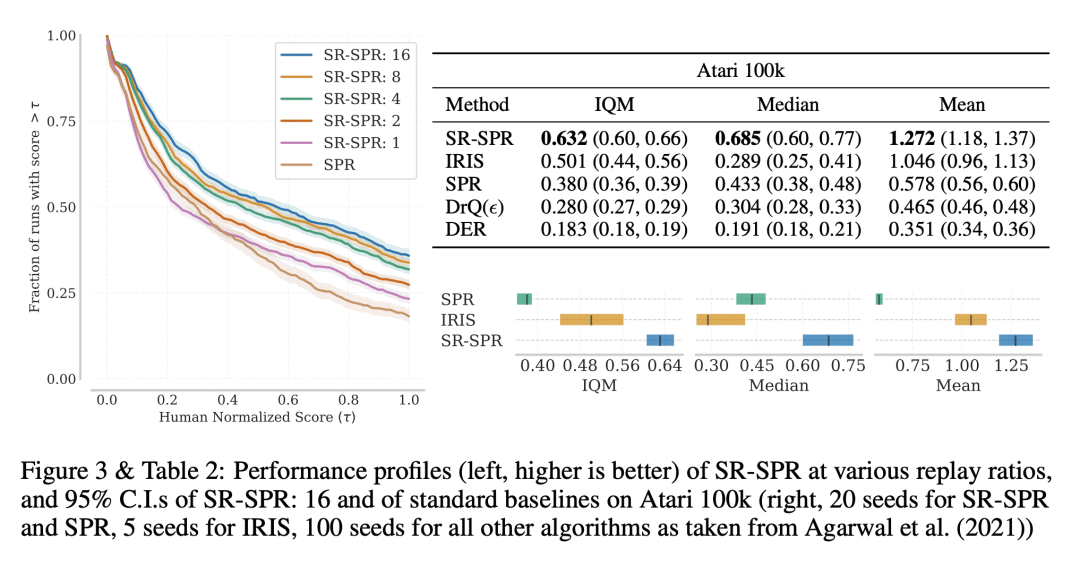
Increasing the replay ratio, the number of updates of an agent’s parameters per environment interaction, is an appealing strategy for improving the sample efficiency of deep reinforcement learning algorithms. In this work, we show that fully or partially resetting the parameters of deep reinforcement learning agents causes better replay ratio scaling capabilities to emerge. We push the limits of the sample efficiency of carefully-modified algorithms by training them using an order of magnitude more updates than usual, significantly improving their performance in the Atari 100k and DeepMind Control Suite benchmarks. We then provide an analysis of the design choices required for favorable replay ratio scaling to be possible and discuss inherent limits and tradeoffs.
https://openreview.net/forum?id=OpC-9aBBVJe



2、[LG] Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
T Ishida, I Yamane…
[The University of Tokyo & ENSAI/CREST & RIKEN]
二分类贝叶斯误差估计的直接方法
要点:
-
提出了一种直接估计二分类中贝叶斯误差的方法,可用于评估具有最先进性能的分类器和检测测试集过拟合; -
所提方法是无模型和无实例的,甚至可以应用于弱监督数据; -
本文展示了所提方法如何用于估计基准数据集的贝叶斯误差,如 CIFAR-10H 和 Fashion-MNIST-H,以及 ICLR 等学术会议; -
用所提方法进行的实验表明,最近提出的深度网络,如Vision Transformer,可能已经达到或即将达到基准数据集的贝叶斯误差。
一句话总结:
用不确定性标签来估计二分类中贝叶斯误差的简单而直接的方法,可检测测试集过拟合,并评估具有最先进性能的分类器。
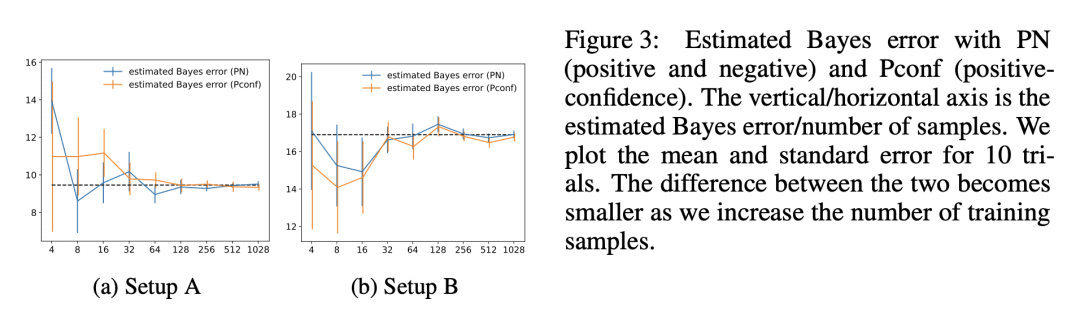
There is a fundamental limitation in the prediction performance that a machine learning model can achieve due to the inevitable uncertainty of the prediction target. In classification problems, this can be characterized by the Bayes error, which is the best achievable error with any classifier. The Bayes error can be used as a criterion to evaluate classifiers with state-of-the-art performance and can be used to detect test set overfitting. We propose a simple and direct Bayes error estimator, where we just take the mean of the labels that show emph{uncertainty} of the class assignments. Our flexible approach enables us to perform Bayes error estimation even for weakly supervised data. In contrast to others, our method is model-free and even instance-free. Moreover, it has no hyperparameters and gives a more accurate estimate of the Bayes error than several baselines empirically. Experiments using our method suggest that recently proposed deep networks such as the Vision Transformer may have reached, or is about to reach, the Bayes error for benchmark datasets. Finally, we discuss how we can study the inherent difficulty of the acceptance/rejection decision for scientific articles, by estimating the Bayes error of the ICLR papers from 2017 to 2023.
https://openreview.net/forum?id=FZdJQgy05rz



3、[LG] Conceptual SCAN: Learning With and About Rules
N Scales, N Schärli, A Babiker, Y Liu, M Dehghani, O Bousquet
[Google]
Conceptual SCAN: 规则的学习与理解
要点:
-
从规则和例子中学习,并对学到的抽象概念进行反思的能力,对人类智能很重要,但在最先进的机器学习架构中,缺乏评估这种能力的基准; -
提出一种构建基准的方法,这些基准显式地提供并询问与给定任务相关的规则,并提出一个简单的数据集,用这种方法分析基于T5的模型的性能; -
在该设置下确定了四个挑战领域:学到的规则和它们的应用之间的一致性,扩展到更大的规则集,构成性的泛化,以及处理有限的训练数据; -
提出概念学习任务(CLT),以评估归纳和演绎学习的结合,提出一种名为概念SCAN(cSCAN)的 CLT 的第一个实例,其确定了基线机器学习架构中需要改进的地方。
一句话总结:
提出概念SCAN基准,一种旨在评估归纳和演绎学习的结合的学习任务,并指出在保持所学规则和它们的应用之间的一致性、扩展到更大的规则集、构成性泛化以及处理有限训练数据方面的挑战。
The ability to learn from a mix of rules and examples and to reflect on the learned abstractions is an important aspect of human intelligence. At the same time, there is a lack of benchmarks that systematically test for this ability, which makes it hard to evaluate the degree to which it is present in state-of-the-art ML architectures. We introduce a method to systematically construct such benchmarks by using an example structure that allows us to explicitly provide and ask about rules that are relevant for the given task. We present a simple dataset that is constructed according to this method, and we use it to analyze the performance of a variety of T5-based machine learning models. We identify four challenge areas in this setup: maintaining consistency between learned rules and their application, scaling to larger rule sets, compositional generalization, and dealing with limited training data.
https://openreview.net/forum?id=2iu9NhxX23



4、[LG] Fully Online Meta Learning
J Rajasegaran, C Finn, S Levine
[UC Berkeley & Stanford University & Google]
全在线元学习
要点:
-
元学习可以加速对不断变化的任务和输入分布的自适应; -
FOML 是一种全在线元学习算法,不需要关于任务边界的真值知识,并在先前看到的数据的缓冲区中不断地更新其在线参数,从而使自适应速度更快,错误率更低; -
FOML 在整个在线自适应过程中只保持两个参数向量,使其概念简单; -
FOML 在简单的连续图像分类任务和基于 CIFAR100 数据集的更复杂的基准上,都优于强基线和最先进的在线元学习方法。
一句话总结:
FOML 是一种全在线元学习算法,可以更快地学习新的任务,而不需要任务边界的真值知识或在任务之间重新设置参数。
While deep networks can learn complex functions such as classifiers, detectors, and trackers, many applications require models that continually adapt to changing input distributions, changing tasks, and changing environmental conditions. Indeed, this ability to continuously accrue knowledge and use past experience to learn new tasks quickly in continual settings is one of the key properties of an intelligent system. For complex and high-dimensional problems, simply updating the model continually with standard learning algorithms such as gradient descent may result in slow adaptation. Meta-learning can provide a powerful tool to accelerate adaptation yet is conventionally studied in batch settings. In this paper, we study how meta-learning can be applied to tackle online problems of this nature, simultaneously adapting to changing tasks and input distributions and meta-training the model in order to adapt more quickly in the future. Extending meta-learning into the online setting presents its own challenges, and although several prior methods have studied related problems, they generally require a discrete notion of tasks, with known ground-truth task boundaries. Such methods typically adapt to each task in sequence, resetting the model between tasks, rather than adapting continuously across tasks. In many real-world settings, such discrete boundaries are unavailable, and may not even exist. To address these settings, we propose a Fully Online Meta-Learning (FOML) algorithm, which does not require any ground truth knowledge about the task boundaries and stays fully online without resetting back to pre-trained weights. Our experiments show that FOML was able to learn new tasks faster than the state-of-the-art online learning methods on Rainbow-MNIST, CIFAR100 and CELEBA datasets.
https://openreview.net/forum?id=eLxADkHrBcR




5、[LG] Offline Reinforcement Learning from Heteroskedastic Data Via Support Constraints
A Singh, A Kumar, q vuong, Y Chebotar, S Levine
[UC Berkeley & University of California, San Diego]
基于支持约束的异方差数据离线强化学习
要点:
-
现有的离线强化学习方法,无法从具有非均匀变异性表现行为的数据集中学习,但所提方法CQL(ReDS)在广泛的离线强化学习问题中提高了性能; -
异方差数据集很可能在现实世界中遇到,而简单的分布约束算法在这种情况下可能是高度无效的; -
该方法通过重加权将分布约束转化为基于支持的约束,允许学到的策略在每个状态下选择如何紧跟行为策略以最大化长期回报; -
CQL(ReDS)继承了现有的超参数值,只对保守的Q-learning(一种最近的离线强化学习方法)所采用的正则化和设计决策的形式进行了最小的改变。
一句话总结:
提出一种通过重加权将分布约束转化为支持约束的异方差数据离线强化学习新方法。
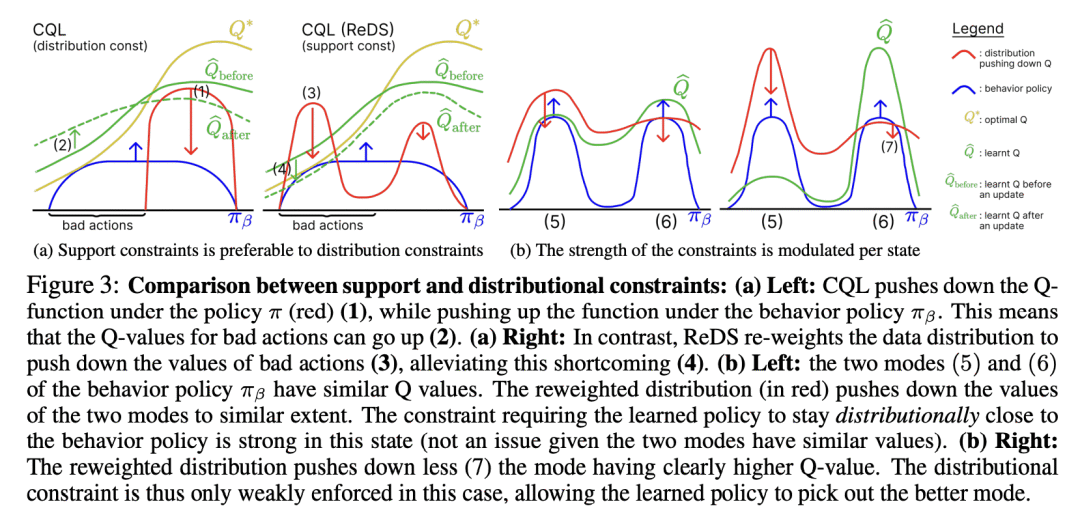
Offline reinforcement learning (RL) learns policies entirely from static datasets, thereby avoiding the challenges associated with online data collection. Practical applications of offline RL will inevitably require learning from datasets where the variability of demonstrated behaviors changes non-uniformly across the state space. For example, at a red light, nearly all human drivers behave similarly by stopping, but when merging onto a highway, some drivers merge quickly, efficiently, and safely, while many hesitate or merge dangerously. We show that existing popular offline RL methods based on distribution constraints fail to learn from data with such non-uniform change in the variability of demonstrated behaviors, often due to the requirement to stay close to the behavior policy to the same extent across the state space. We demonstrate this failure mode both theoretically and experimentally. Ideally, the learned policy should be free to choose per-state how closely to follow the behavior policy to maximize long-term return, as long as the learned policy stays within the support of the behavior policy. To instantiate this principle, we reweight the data distribution in conservative Q-learning and show that support constraints emerge when doing so. The reweighted distribution is a mixture of the current policy and an additional policy trained to mine poor actions that are likely under the behavior policy. Our method CQL (ReDS) is simple, theoretically motivated, and improves performance across a wide range of offline RL problems in Atari games, navigation, and pixel-based manipulation.
https://openreview.net/forum?id=Rg1LG7wtd2D


另外几篇值得关注的论文:
[RO] Open-World Object Manipulation using Pre-trained Vision-Language Models
A Stone, T Xiao, Y Lu, K Gopalakrishnan, K Lee, Q Vuong, P Wohlhart, B Zitkovich, F Xia, C Finn, K Hausman
[Robotics at Google]
基于预训练视觉-语言模型的开放世界对象操纵
要点:
-
使用预训练视觉-语言模型可以大幅提高机器人策略的通用性; -
MOO 可以将零样本推广到广泛的新物体类别和环境; -
MOO 可进行扩展以实现开放世界的导航和操纵; -
在处理涉及空间关系的复杂物体描述方面,MOO有局限性。
一句话总结:
机器人可以学习将人类语言与感知观察和行动联系起来,使用预训练的视觉-语言模型来完成涉及之前未见过物体类别的新指令。
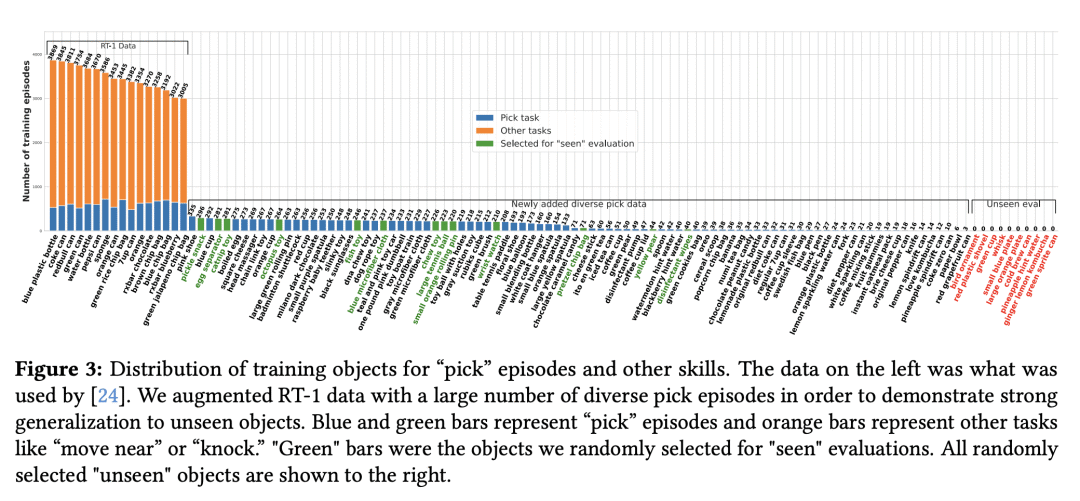
For robots to follow instructions from people, they must be able to connect the rich semantic information in human vocabulary, e.g. “can you get me the pink stuffed whale?” to their sensory observations and actions. This brings up a notably difficult challenge for robots: while robot learning approaches allow robots to learn many different behaviors from first-hand experience, it is impractical for robots to have first-hand experiences that span all of this semantic information. We would like a robot’s policy to be able to perceive and pick up the pink stuffed whale, even if it has never seen any data interacting with a stuffed whale before. Fortunately, static data on the internet has vast semantic information, and this information is captured in pre-trained vision-language models. In this paper, we study whether we can interface robot policies with these pre-trained models, with the aim of allowing robots to complete instructions involving object categories that the robot has never seen first-hand. We develop a simple approach, which we call Manipulation of Open-World Objects (MOO), which leverages a pre-trained vision-language model to extract object-identifying information from the language command and image, and conditions the robot policy on the current image, the instruction, and the extracted object information. In a variety of experiments on a real mobile manipulator, we find that MOO generalizes zero-shot to a wide range of novel object categories and environments. In addition, we show how MOO generalizes to other, non-language-based input modalities to specify the object of interest such as finger pointing, and how it can be further extended to enable open-world navigation and manipulation. The project’s website and evaluation videos can be found at this https URL
https://arxiv.org/abs/2303.00905



[LG] Differentially Private Diffusion Models Generate Useful Synthetic Images
S Ghalebikesabi, L Berrada, S Gowal, I Ktena, R Stanforth, J Hayes, S De, S L. Smith, O Wiles, B Balle
[DeepMind & University of Oxford]
基于差分隐私扩散模型生成有用的合成图像
要点:
-
扩散模型可以用差分隐私进行训练,以产生有用的、可证明的隐私合成数据,即使在预训练和微调分布之间有明显的分布变化的应用中也是如此; -
在开放数据(ImageNet)上进行预训练,可以大大超过最近在类似主题上的工作结果,可完成比之前方法大45倍模型的准确训练; -
通过利用更大的合成数据集和集成,下游分类器的准确性可以在没有额外隐私成本的情况下得到明显改善; -
提出的评估框架更适合从业者的需求,他们会使用查分隐私合成数据作为私有数据集的替代品。
一句话总结:
展示了查分隐私扩散模型生成高质量合成图像的能力,保留了训练数据的隐私,突破了目前受数据可用性限制的机器学习应用。
The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
https://arxiv.org/abs/2302.13861




[CL] Interactive Text Generation
F Faltings, M Galley, B Peng, K Brantley, W Cai, Y Zhang, J Gao, B Dolan
[Microsoft & MIT & Cornell University]
交互式文本生成
要点:
-
与非交互式模型相比,使用用户模拟器的交互文本生成能实现更高的文本质量,即使用户输入量相同; -
所提框架以相同的用户输入或编辑的预算来评估生成模型,确保交互和非交互模型之间的公平比较; -
使用模仿学习训练的基于 Transformer 的交互式文本编辑模型,包括非自回归模型,取得了最佳效果; -
贡献了不同的用户模拟器,而模型的性能保持一致,突出了新基准的鲁棒性。
一句话总结:
与非交互式模型相比,使用用户模拟器的交互式文本生成实现了更高的文本质量,即使用户的输入量相同。
Users interact with text, image, code, or other editors on a daily basis. However, machine learning models are rarely trained in the settings that reflect the interactivity between users and their editor. This is understandable as training AI models with real users is not only slow and costly, but what these models learn may be specific to user interface design choices. Unfortunately, this means most of the research on text, code, and image generation has focused on non-interactive settings, whereby the model is expected to get everything right without accounting for any input from a user who may be willing to help. We introduce a new Interactive Text Generation task that allows training generation models interactively without the costs of involving real users, by using user simulators that provide edits that guide the model towards a given target text. We train our interactive models using Imitation Learning, and our experiments against competitive non-interactive generation models show that models trained interactively are superior to their non-interactive counterparts, even when all models are given the same budget of user inputs or edits.
https://arxiv.org/abs/2303.00908




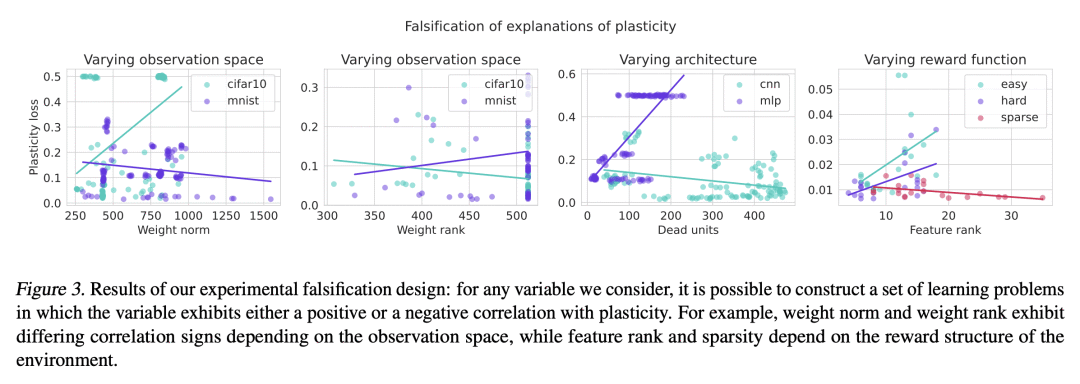
[LG] Understanding plasticity in neural networks
C Lyle, Z Zheng, E Nikishin, B A Pires, R Pascanu, W Dabney
[DeepMind]
理解神经网络的可塑性
要点:
-
训练过程中,神经网络的可塑性损失与损失景观的曲率变化有着深刻的联系; -
可塑性损失通常发生在缺少饱和单元或发散梯度范数的情况下; -
参数化和优化设计的选择,如层规范化,可以在训练过程中更好地保护可塑性; -
稳定损失景观对促进可塑性至关重要,并有许多附带的好处,如更好的泛化。
一句话总结:
研究了深度神经网络在训练过程中的可塑性损失,并确定了稳定损失景观对促进可塑性的重要性。
Plasticity, the ability of a neural network to quickly change its predictions in response to new information, is essential for the adaptability and robustness of deep reinforcement learning systems. Deep neural networks are known to lose plasticity over the course of training even in relatively simple learning problems, but the mechanisms driving this phenomenon are still poorly understood. This paper conducts a systematic empirical analysis into plasticity loss, with the goal of understanding the phenomenon mechanistically in order to guide the future development of targeted solutions. We find that loss of plasticity is deeply connected to changes in the curvature of the loss landscape, but that it typically occurs in the absence of saturated units or divergent gradient norms. Based on this insight, we identify a number of parameterization and optimization design choices which enable networks to better preserve plasticity over the course of training. We validate the utility of these findings in larger-scale learning problems by applying the best-performing intervention, layer normalization, to a deep RL agent trained on the Arcade Learning Environment.
https://arxiv.org/abs/2303.01486








 ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
 tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
 ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
 ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.

