1、[LG] An Information-Theoretic Perspective on Variance-Invariance-Covariance Regularization
2、[LG] Are More Layers Beneficial to Graph Transformers?
3、[CV] StraIT: Non-autoregressive Generation with Stratified Image Transformer
4、[LG] The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning
5、[CV] Collage Diffusion
[CL] Large Language Models Are State-of-the-Art Evaluators of Translation Quality
[CV] BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
[CV] Directed Diffusion: Direct Control of Object Placement through Attention Guidance
[CL] A Survey on Long Text Modeling with Transformers
摘要: 从信息论角度看方差-不变性-协方差正则化、突破图Transformer深度瓶颈、基于分层图像Transformer的非自回归生成、对比学习表示的普适性与标签效率的权衡、拼贴扩散、用大型语言模型评估翻译质量、面向实时视图合成的网格化神经SDF、基于注意力引导的物体位置直接控制、基于Transformer的长文本建模综述
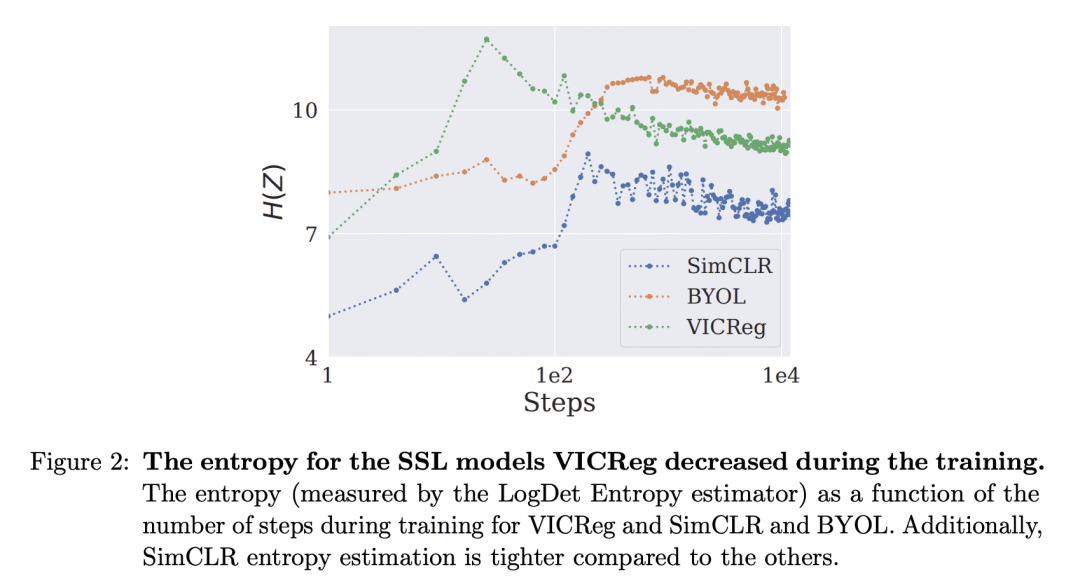
1、[LG] An Information-Theoretic Perspective on Variance-Invariance-Covariance Regularization
R Shwartz-Ziv, R Balestriero, K Kawaguchi, T G. J. Rudner, Y LeCun
[New York University & Meta AI]
从信息论角度看方差-不变性-协方差正则化
要点:
-
将随机性假设迁移到神经网络输入,从信息论角度研究确定性网络; -
VICReg 的目标与信息论的量有关,并强调了目标的基本假设; -
提出一种连接VICReg、信息论和下游泛化的泛化界; -
提出信息论的自监督学习方法,并对其进行经验验证,以改善迁移学习。
一句话总结:
从信息论的角度阐述了用于自监督学习的方差-不变性-协方差正则化(VICReg),并提出了新的自监督学习方法,性能优于现有方法。
In this paper, we provide an information-theoretic perspective on Variance-Invariance-Covariance Regularization (VICReg) for self-supervised learning. To do so, we first demonstrate how information-theoretic quantities can be obtained for deterministic networks as an alternative to the commonly used unrealistic stochastic networks assumption. Next, we relate the VICReg objective to mutual information maximization and use it to highlight the underlying assumptions of the objective. Based on this relationship, we derive a generalization bound for VICReg, providing generalization guarantees for downstream supervised learning tasks and present new self-supervised learning methods, derived from a mutual information maximization objective, that outperform existing methods in terms of performance. This work provides a new information-theoretic perspective on self-supervised learning and Variance-Invariance-Covariance Regularization in particular and guides the way for improved transfer learning via information-theoretic self-supervised learning objectives.
https://arxiv.org/abs/2303.00633


2、[LG] Are More Layers Beneficial to Graph Transformers?
H Zhao, S Ma, D Zhang, Z Deng, F Wei
[Microsoft Research & Peking University]
突破图Transformer深度瓶颈
要点:
-
由于全局注意力的能力有限,目前的图Ttransformer 有深度限制; -
基于子结构的局部注意力机制可以促进对更深的图 Transformer 的局部子结构特征的注意,并提高所学表示的表达能力; -
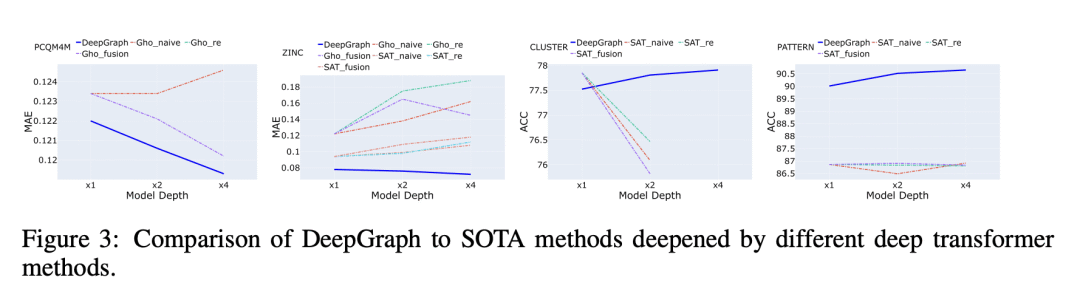
DeepGraph 是一种新的图 Transformer 模型,采用了子结构标记和局部注意力,在标准图基准上实现了最先进的深度模型性能; -
所提出方法打破了图 Transformer 的深度限制,并证明深度模型学习有效的子结构注意力模式和获得信息丰富的图子结构特征的难度。
一句话总结:
深度图 Transformer 由于全局注意力能力受限,通过增加深度提高性能存在瓶颈,可通过基于子结构的局部注意力来解决。
Despite that going deep has proven successful in many neural architectures, the existing graph transformers are relatively shallow. In this work, we explore whether more layers are beneficial to graph transformers, and find that current graph transformers suffer from the bottleneck of improving performance by increasing depth. Our further analysis reveals the reason is that deep graph transformers are limited by the vanishing capacity of global attention, restricting the graph transformer from focusing on the critical substructure and obtaining expressive features. To this end, we propose a novel graph transformer model named DeepGraph that explicitly employs substructure tokens in the encoded representation, and applies local attention on related nodes to obtain substructure based attention encoding. Our model enhances the ability of the global attention to focus on substructures and promotes the expressiveness of the representations, addressing the limitation of self-attention as the graph transformer deepens. Experiments show that our method unblocks the depth limitation of graph transformers and results in state-of-the-art performance across various graph benchmarks with deeper models.
https://arxiv.org/abs/2303.00579



3、[CV] StraIT: Non-autoregressive Generation with Stratified Image Transformer
S Qian, H Chang, Y Li, Z Zhang, J Jia, H Zhang
[Google Research]
StraIT: 基于分层图像Transformer的非自回归生成
要点:
-
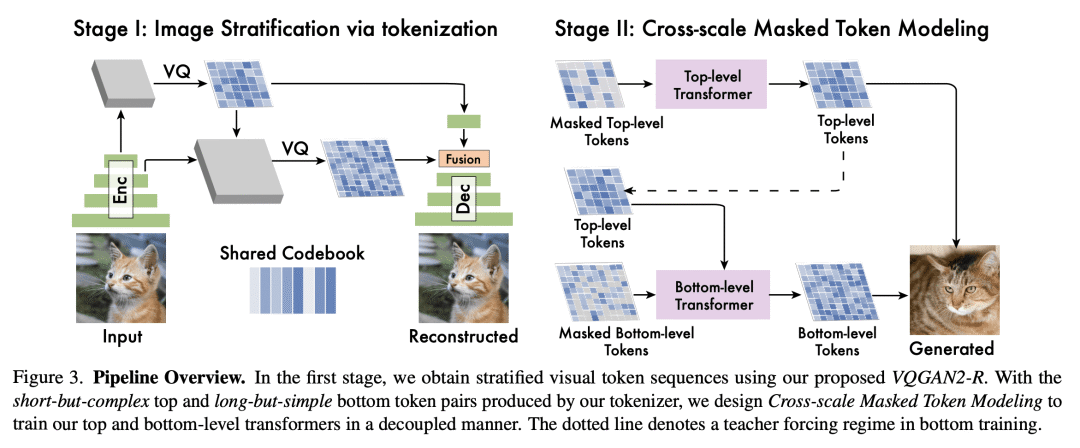
StraIT 是一种分层建模框架,将视觉标记编码为具有涌现属性的分层,缓解了非自回归模型的建模难度; -
StraIT 在 ImageNet 基准上明显优于现有最先进自回归和扩散模型,同时实现了30倍的推理速度; -
StraIT 的解耦建模过程使其在应用上具有多样性,包括语义领域迁移; -
非自回归模型,如 StraIT,是未来生成式建模研究的一个有希望的方向。
一句话总结:
StraIT 是一种纯非自回归(NAR)生成模型,其类条件图像生成优于现有的自回归和扩散模型。
We propose Stratified Image Transformer(StraIT), a pure non-autoregressive(NAR) generative model that demonstrates superiority in high-quality image synthesis over existing autoregressive(AR) and diffusion models(DMs). In contrast to the under-exploitation of visual characteristics in existing vision tokenizer, we leverage the hierarchical nature of images to encode visual tokens into stratified levels with emergent properties. Through the proposed image stratification that obtains an interlinked token pair, we alleviate the modeling difficulty and lift the generative power of NAR models. Our experiments demonstrate that StraIT significantly improves NAR generation and out-performs existing DMs and AR methods while being order-of-magnitude faster, achieving FID scores of 3.96 at 256*256 resolution on ImageNet without leveraging any guidance in sampling or auxiliary image classifiers. When equipped with classifier-free guidance, our method achieves an FID of 3.36 and IS of 259.3. In addition, we illustrate the decoupled modeling process of StraIT generation, showing its compelling properties on applications including domain transfer.
https://arxiv.org/abs/2303.00750



4、[LG] The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning
Z Shi, J Chen, K Li, J Raghuram, X Wu, Y Liang, S Jha
[University of Wisconsin-Madison & Google]
对比学习表示的普适性与标签效率的权衡
要点:
-
用对比学习和线性探测对表示进行预训练,是下游任务的一个流行范式; -
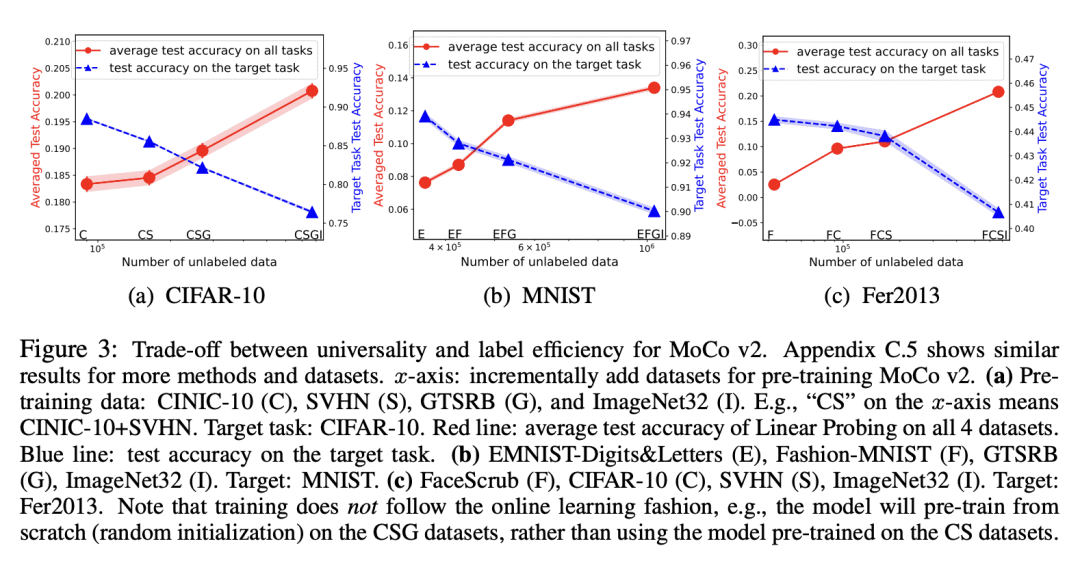
在标签效率和对比学习的表示的普适性之间存在着权衡; -
更多多样的预训练数据,导致不同任务的特征更加多样化,提高了普适性,但由于更大的样本复杂性,预测性能会变差; -
对比正则化方法可以用来改善标签效率和普适性之间的权衡。
一句话总结:
研究了对比学习预训练的表示在普适性和标签效率间的权衡,提出一种对比正则化方法来改善这种权衡。
Pre-training representations (a.k.a. foundation models) has recently become a prevalent learning paradigm, where one first pre-trains a representation using large-scale unlabeled data, and then learns simple predictors on top of the representation using small labeled data from the downstream tasks. There are two key desiderata for the representation: label efficiency (the ability to learn an accurate classifier on top of the representation with a small amount of labeled data) and universality (usefulness across a wide range of downstream tasks). In this paper, we focus on one of the most popular instantiations of this paradigm: contrastive learning with linear probing, i.e., learning a linear predictor on the representation pre-trained by contrastive learning. We show that there exists a trade-off between the two desiderata so that one may not be able to achieve both simultaneously. Specifically, we provide analysis using a theoretical data model and show that, while more diverse pre-training data result in more diverse features for different tasks (improving universality), it puts less emphasis on task-specific features, giving rise to larger sample complexity for down-stream supervised tasks, and thus worse prediction performance. Guided by this analysis, we propose a contrastive regularization method to improve the trade-off. We validate our analysis and method empirically with systematic experiments using real-world datasets and foundation models.
https://arxiv.org/abs/2303.00106



5、[CV] Collage Diffusion
V Sarukkai, L Li, A Ma, C Ré, K Fatahalian
[Stanford University]
Collage Diffusion
要点:
-
拼贴扩散(Collage Diffusion)是一种拼贴条件扩散算法,使用户能生成高质量、多样化的图像,并对有多个物体场景的图像输出进行精确控制; -
用户通过定义一个拼贴来控制图像的生成:一个文本提示与一个有序的图层序列配对,其中每一层是一个RGBA图像和一个相应的文本提示; -
Collage Diffusion 用各层的 alpha 蒙版来修改文本-图像的交叉注意力,并学习每层的专门文本表示,以保持个别拼贴层的特征,而这些特征并非由文本指定; -
拼贴输入可以实现基于层的控制,对最终输出进行精细控制,允许用户在逐层基础上控制图像的协调性,并在保持其他对象固定的情况下编辑生成的图像中的个别对象。
一句话总结:
Collage Diffusion 是一种拼贴条件扩散算法,使用户能生成高质量、多样化的图像,通过将文本提示和 alpha 合成RGBA层进行组合,对多物体场景的图像输出进行精确控制。
Text-conditional diffusion models generate high-quality, diverse images. However, text is often an ambiguous specification for a desired target image, creating the need for additional user-friendly controls for diffusion-based image generation. We focus on having precise control over image output for scenes with several objects. Users control image generation by defining a collage: a text prompt paired with an ordered sequence of layers, where each layer is an RGBA image and a corresponding text prompt. We introduce Collage Diffusion, a collage-conditional diffusion algorithm that allows users to control both the spatial arrangement and visual attributes of objects in the scene, and also enables users to edit individual components of generated images. To ensure that different parts of the input text correspond to the various locations specified in the input collage layers, Collage Diffusion modifies text-image cross-attention with the layers’ alpha masks. To maintain characteristics of individual collage layers that are not specified in text, Collage Diffusion learns specialized text representations per layer. Collage input also enables layer-based controls that provide fine-grained control over the final output: users can control image harmonization on a layer-by-layer basis, and they can edit individual objects in generated images while keeping other objects fixed. Collage-conditional image generation requires harmonizing the input collage to make objects fit together–the key challenge involves minimizing changes in the positions and key visual attributes of objects in the input collage while allowing other attributes of the collage to change in the harmonization process. By leveraging the rich information present in layer input, Collage Diffusion generates globally harmonized images that maintain desired object locations and visual characteristics better than prior approaches.
https://arxiv.org/abs/2303.00262




另外几篇值得关注的论文:
[CL] Large Language Models Are State-of-the-Art Evaluators of Translation Quality
T Kocmi, C Federmann
[Microsoft]
用大型语言模型评估翻译质量
要点:
-
GEMBA是一种基于GPT的翻译质量评估指标,在有参考译文和没有参考译文的情况下都能发挥作用,在 MQM 2022 测试集的三种语言对上达到了最先进的准确性; -
该翻译质量评估方法仅适用于 GPT 3.5 和更大的模型,而受限最少的提示模板取得了最佳性能; -
GEMBA 在语段层面上还不够可靠,只能应用于系统级评估; -
像 GPT 这样的大型语言模型在翻译质量评估方面有很大的潜力,并可能使文档级评估取得进展,但还需要进一步研究,以通过少样本学习和模型微调提高准确性。
一句话总结:
GEMBA 是一种基于 GPT 的指标,在翻译质量评估方面达到了最先进的准确性,无论有没有参考译文,都能发挥作用。
We describe GEMBA, a GPT-based metric for assessment of translation quality, which works both with a reference translation and without. In our evaluation, we focus on zero-shot prompting, comparing four prompt variants in two modes, based on the availability of the reference. We investigate seven versions of GPT models, including ChatGPT. We show that our method for translation quality assessment only works with GPT 3.5 and larger models. Comparing to results from WMT22’s Metrics shared task, our method achieves state-of-the-art accuracy in both modes when compared to MQM-based human labels. Our results are valid on the system level for all three WMT22 Metrics shared task language pairs, namely English into German, English into Russian, and Chinese into English. This provides a first glimpse into the usefulness of pre-trained, generative large language models for quality assessment of translations. We publicly release all our code and prompt templates used for the experiments described in this work, as well as all corresponding scoring results, to allow for external validation and reproducibility.
https://arxiv.org/abs/2302.14520


[CV] BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
L Yariv, P Hedman, C Reiser, D Verbin, P P. Srinivasan, R Szeliski, J T. Barron, B Mildenhall
[Google Research]
BakedSDF: 面向实时视图合成的网格化神经SDF
要点:
-
提出了一种新方法 BakedSDF,用于重建大型无界真实世界场景的高质量网格,以进行实时视图合成; -
用混合神经体-表面场景表示法,为准确的表面重建进行了优化,然后 bake 成具有与视图相关的外观模型的三角形网格; -
BakedSDF 在精度、速度和功耗方面优于之前的实时渲染场景表示,可产生高质量的网格,使下游应用如外观编辑和物理模拟成为可能; -
该系统可以在消费级设备上以实时帧率进行渲染,产生的网格准确而详细,可以实现标准的图形应用。
一句话总结:
BakedSDF 是一种重建大型无界真实世界场景高质量网格的方法,适用于逼真新视图合成,在精度、速度和功耗方面优于之前的实时渲染的场景表示,可产生高质量的网格,使下游应用成为可能。
We present a method for reconstructing high-quality meshes of large unbounded real-world scenes suitable for photorealistic novel view synthesis. We first optimize a hybrid neural volume-surface scene representation designed to have well-behaved level sets that correspond to surfaces in the scene. We then bake this representation into a high-quality triangle mesh, which we equip with a simple and fast view-dependent appearance model based on spherical Gaussians. Finally, we optimize this baked representation to best reproduce the captured viewpoints, resulting in a model that can leverage accelerated polygon rasterization pipelines for real-time view synthesis on commodity hardware. Our approach outperforms previous scene representations for real-time rendering in terms of accuracy, speed, and power consumption, and produces high quality meshes that enable applications such as appearance editing and physical simulation.
https://arxiv.org/abs/2302.14859




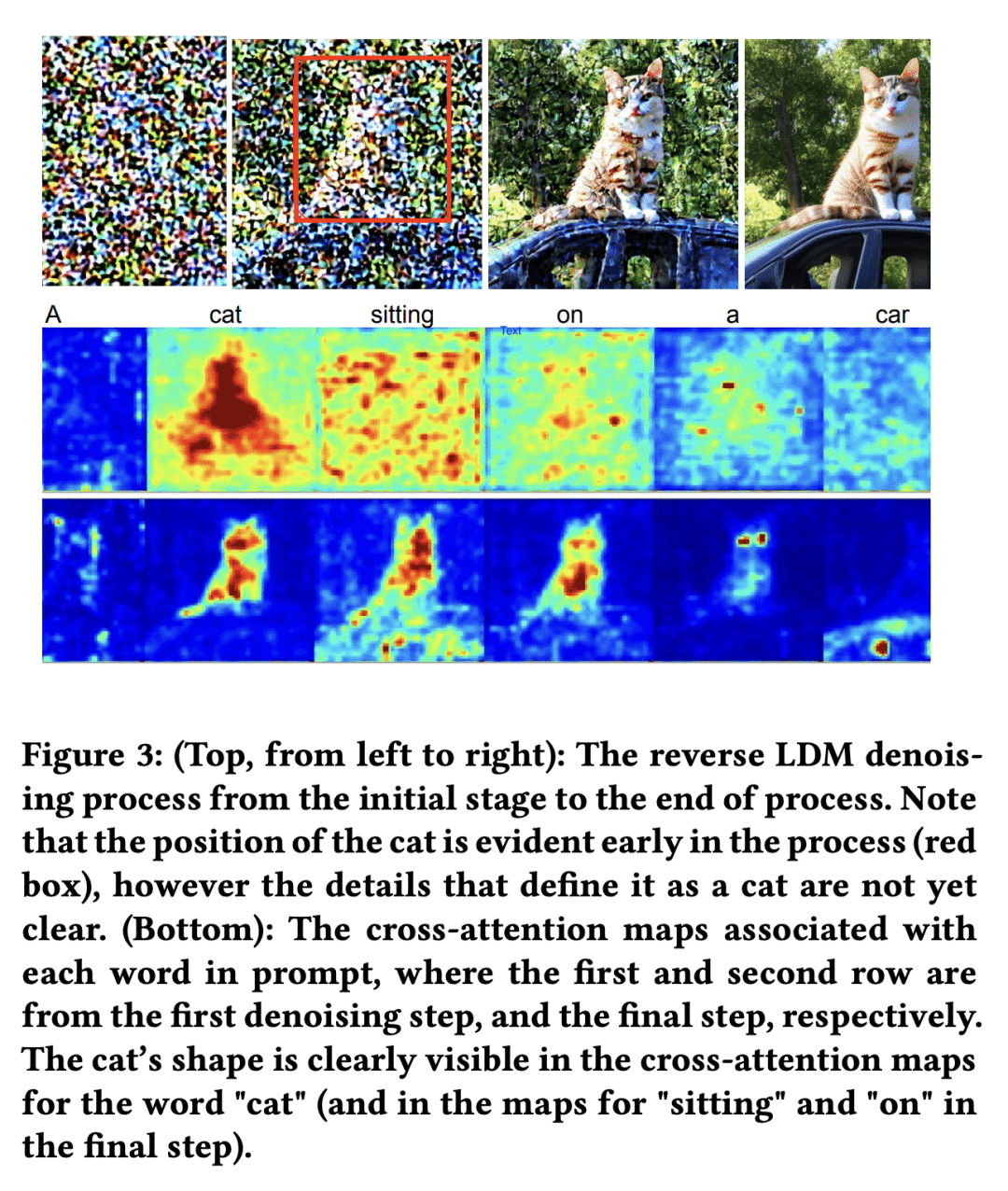
[CV] Directed Diffusion: Direct Control of Object Placement through Attention Guidance
W K Ma, J.P. Lewis, W. B Kleijn, T Leung
[Google Research & Victoria University of Wellington]
Directed Diffusion: 基于注意力引导的物体位置直接控制
要点:
-
文字引导的扩散模型,可以从简短的文字提示产生高质量的图像,但在将多个物体放置在指定位置时却很困难; -
定向扩散方法在交叉注意力图中对应于被控制物体的理想位置注入”激活”,从而使被定位的物体和背景之间形成一致的融合; -
定向扩散是朝着将文字引导的扩散模型的适用性从单幅图像推广到相关图像集的方向迈出的一步; -
定向扩散只需要对一个广泛使用的库进行几行代码修改,并允许用户通过指定近似的边框来控制物体的放置。
一句话总结:
定向扩散(Directed Diffusion)通过注意力引导实现了对物体位置的直接控制,简化了文本到图像模型的图像编辑,并为将文本引导的扩散模型的适用性从单幅图像推广到相关图像集推进了一步。
Text-guided diffusion models such as DALLE-2, IMAGEN, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are very high quality as well. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. Unfortunately, this capability to “direct” the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work we take a particularly straightforward approach to providing the needed direction, by injecting “activation” at desired positions in the cross-attention maps corresponding to the objects under control, while attenuating the remainder of the map. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. To the best of our knowledge, our Directed Diffusion method is the first diffusion technique that provides positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
https://arxiv.org/abs/2302.13153



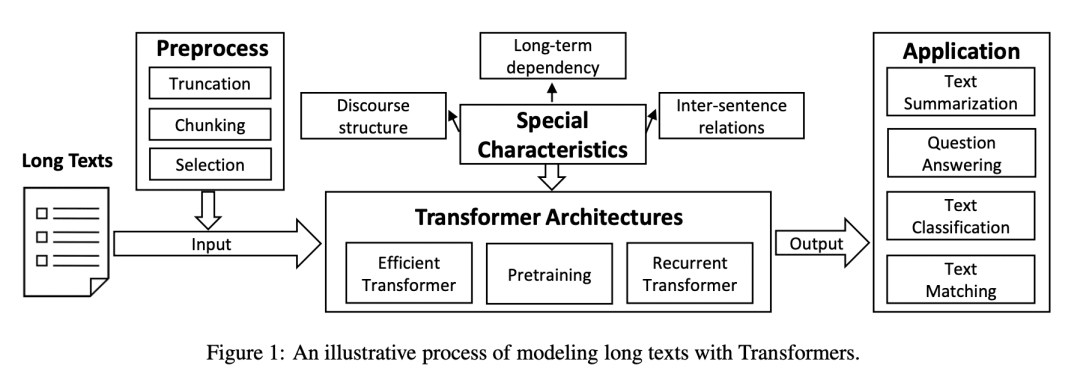
[CL] A Survey on Long Text Modeling with Transformers
Z Dong, T Tang, L Li, W X Zhao
[Renmin University of China]
基于Transformer的长文本建模综述
要点:
-
长文本建模在NLP中很重要,但对现有的文本模型提出了挑战; -
预处理技术和改进的 Transformer 架构是对长文本进行有效建模的关键; -
Transformer 模型可以自适应以捕捉长文本的特有特征; -
长文本建模可应用于摘要、分类和对话系统等领域。
一句话总结:
本文综述了近年来使用 Transformer 进行长文本建模的研究进展,包括预处理技术、高效体系结构、长文本的特殊性以及典型应用和未来发展方向。
Modeling long texts has been an essential technique in the field of natural language processing (NLP). With the ever-growing number of long documents, it is important to develop effective modeling methods that can process and analyze such texts. However, long texts pose important research challenges for existing text models, with more complex semantics and special characteristics. In this paper, we provide an overview of the recent advances on long texts modeling based on Transformer models. Firstly, we introduce the formal definition of long text modeling. Then, as the core content, we discuss how to process long input to satisfy the length limitation and design improved Transformer architectures to effectively extend the maximum context length. Following this, we discuss how to adapt Transformer models to capture the special characteristics of long texts. Finally, we describe four typical applications involving long text modeling and conclude this paper with a discussion of future directions. Our survey intends to provide researchers with a synthesis and pointer to related work on long text modeling.
https://arxiv.org/abs/2302.14502




 ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
 tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
 ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
 ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.


