## 前言
之前我整理收藏的图片时,都是简单粗暴地直接全部重命名为hash值,然后配合mongodb管理网络链接(参见[python+mongodb+php个人管理图片方案](https://www.sitstars.com/archives/64/)),后来也加上了机器学习给不少图片打上了标签(参见[用DeepDanbooru为二次元图片打上标签并存入数据库中](https://www.sitstars.com/archives/75/)),并且搞出了一个随机图API(参见[用fastapi搭建随机图api](https://www.sitstars.com/archives/87/))。
但是最近参观了几个随机图API,发现有的返回值更加丰富,不仅有图床链接,而且还有作者ID、标题等。突然觉得有必要也整一个,要不然和转载别人文章不标明出处的行为有什么区别。所以就有了这一篇文章。
首先介绍一下思路,人工找图片来源的方法一般是借助搜索引擎(比如谷歌识图、百度识图),还有些专门针对二次元图片搜索的网站(比如[ascii2d](https://ascii2d.net/)、[saucenao](https://saucenao.com/))。那么只要我借助python批量上传检索,不就可以自动化找到来源了吗?
## 图片压缩
之所以要进行图片压缩,是为了减少图片上传的耗时,也避免给搜索引擎带来压力导致ip被封。我一开始想的就是直接用python库压缩,但是找了一下,貌似没有比较满意的解决方案。不是压缩效果不理想(Pillow模块),就是需要上传到云端压缩(TinyPNG),或者是压缩时间较长(squoosh)。
所以专业的事情交给专业的软件去做,直接请出大杀器Caesium(大家可以网上找找破解版),它压缩速度快而且效果明显(大小减少很多且清晰度没有明显变化)。7000张图片,大概等了十几分钟就压缩完毕,原本10个G的文件夹一下子就变成了2个G。
这里需要注意的是,压缩版的图片只是为了搜索,所以质量稍微损失一点是没关系的,一定注意不要覆盖掉原始文件夹,最好统一输出到另外一个文件夹。
## 图片搜索引擎
既然我需要找的都是二次元图片,那么[ascii2d](https://ascii2d.net/)、[saucenao](https://saucenao.com/)显然要比谷歌百度要好,不仅是因为它们更精确,而且还会输出原始链接、标题、作者,其中saucenao甚至还会输出p站id。不用考虑,就它们了。
接下来的难题就是如何使用python上传了,我对爬虫这块不太熟,所以在网上找了一下看有没有别人写好的代码。没想到直接搜到了一个完整的轮子,[PicImageSearch](https://github.com/kitUIN/PicImageSearch),它封装了几个搜索引擎,提供了统一风格的API。安装使用也比较简单,参见[说明文档](http://www.kituin.cf/wiki/picimagesearch/)。
安装:
“`python
pip install PicImageSearch -i https://pypi.tuna.tsinghua.edu.cn/simple
“`
看了说明文档我才知道原来saucenao是有API的,不过免费账户有限制,30秒最多搜索5次,24小时最多搜索200次,免费是足够了,但对我7000+的图片来说,有点不够看。原本想的是几个搜索引擎轮番调用,然后多申请几个saucenao账号。但是想了想这又加大了工作量,而且saucenao确实也好用(上传速度快,搜索结果精确,而且返回值更多),所以干脆花钱买省心吧。
直接在[这里](https://saucenao.com/user.php?page=account-upgrades)升级,遗憾的是它只支持信用卡。我尝试给管理员发邮件提出paypal支付,回复说是可以的,于是我就有了个VIP账户。看了一下30秒内可以搜索25次,每天可以搜索5000次,完全满足需求。
## 数据保存
数据保存方案就选择sqlite了,反正都是结构化的数据。不过这里还需要再配合数据写一个判断条件,当前搜索的图片若已存在于数据库中,就跳过,防止重复搜索。
另外说一下我的图片文件结构。
“`plaintext
项目根目录
—-压缩后
—-搜索完毕
—-搜索失败
—-缩略图
“`
这里的缩略图也是从saucenao下的,这样方便我们人工核对一遍。
## 代码
“`python
from pathlib import Path
from PicImageSearch import SauceNAO
import sqlite3
import shutil
import time
program_dir = Path(r’D:素材’)
pic_dir = program_dir / ‘压缩后’ # 待搜索的图片文件夹
suo_dir = program_dir / ‘缩略图’ # 搜索完毕后缩略图存放地
SauceNAO_api = ‘这里填写你的API’
pic_path_list = pic_dir.iterdir()
db_path = program_dir / ‘pic.db’
con = sqlite3.connect(db_path)
cur = con.cursor()
# 新建表acg,若已有该表则忽略,
cur.execute(“CREATE TABLE IF NOT EXISTS acg(hash TEXT, title TEXT, author TEXT, url TEXT,pixiv_id INT,member_id INT)”)
exists_list = cur.execute(“SELECT hash FROM acg”).fetchall()
exists_list = [x[0] for x in exists_list] # 已存在的hash表
def insert_db(res):
cur.execute(“INSERT INTO acg(hash,title,author,url,pixiv_id,member_id) VALUES(?,?,?,?,?,?)”,res)
con.commit()
def move_pic(pic_path, target_dir):
target_path = pic_path.parent.parent / target_dir / pic_path.name
shutil.move(pic_path, target_path)
def search_img(pic_path, source= ‘saucenao’):
flag = True
pic_hash = pic_path.stem
if pic_hash in exists_list:
print(pic_hash,’已存在,跳过’)
return
suo_path = suo_dir / pic_path.name # 缩略图
if source == ‘saucenao’: # 每30秒25个,每天5000个(普通账户5/200)
saucenao = SauceNAO(api_key=SauceNAO_api,numres = 1,minsim = 80,output_type = 2)
res = saucenao.search(str(pic_path))
if res.results_requested > 0:
title = res.raw[0].title
author = res.raw[0].author
url = res.raw[0].url
pixiv_id = res.raw[0].pixiv_id
member_id = res.raw[0].member_id
res.raw[0].download_thumbnail(filename=suo_path)
result = (pic_hash, title, author, url, pixiv_id, member_id)
insert_db(result)
print(‘{}搜索成功,结果为:’.format(pic_hash), result)
else:
print(‘{}搜索失败’.format(source))
flag = False
print(’30秒内剩余次数:{},24小时内剩余次数:{}’.format(res.short_remaining, res.long_remaining))
if res.short_remaining == 0:
print(‘一小时内无法使用saucenao’)
if res.long_remaining == 0:
print(‘二十四小时内无法使用saucenao’)
if flag:
move_pic(pic_path, ‘搜索完毕’)
else:
move_pic(pic_path, ‘搜索失败’)
for pic_path in pic_path_list:
try:
search_img(pic_path, source= ‘saucenao’)
except:
time.sleep(10)
“`
效果:
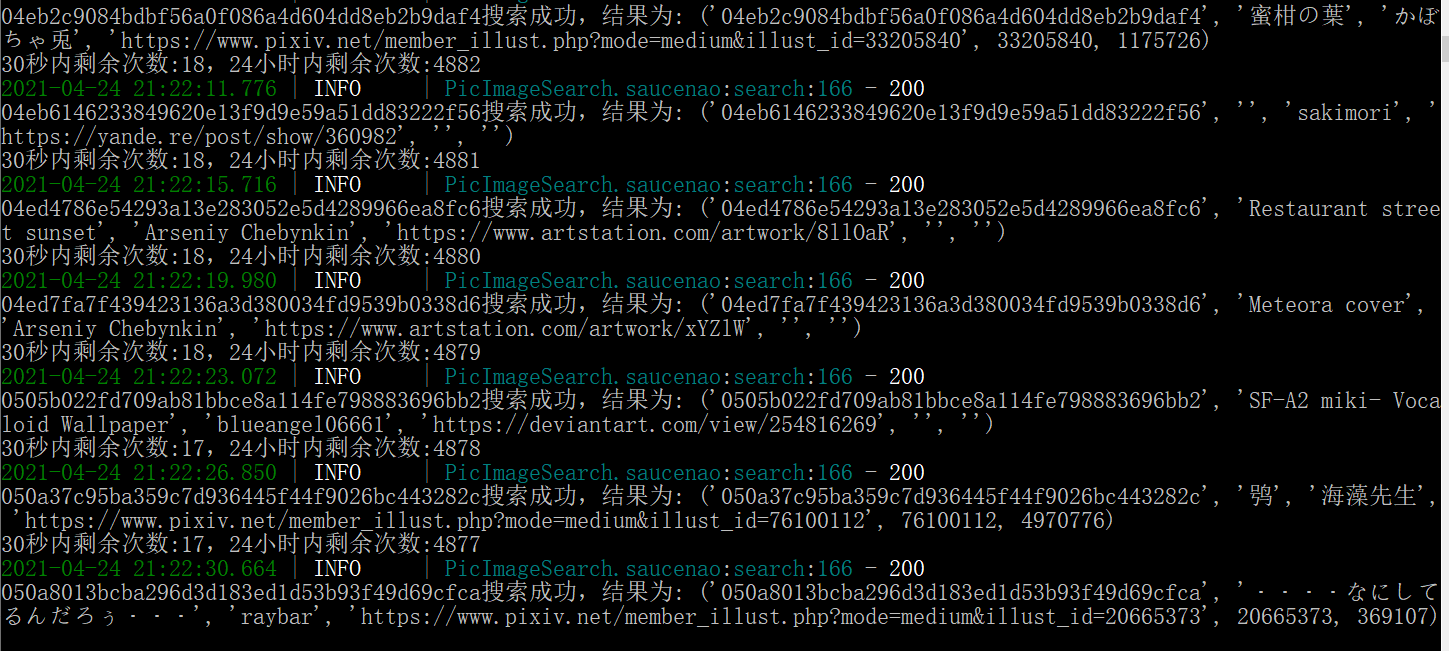
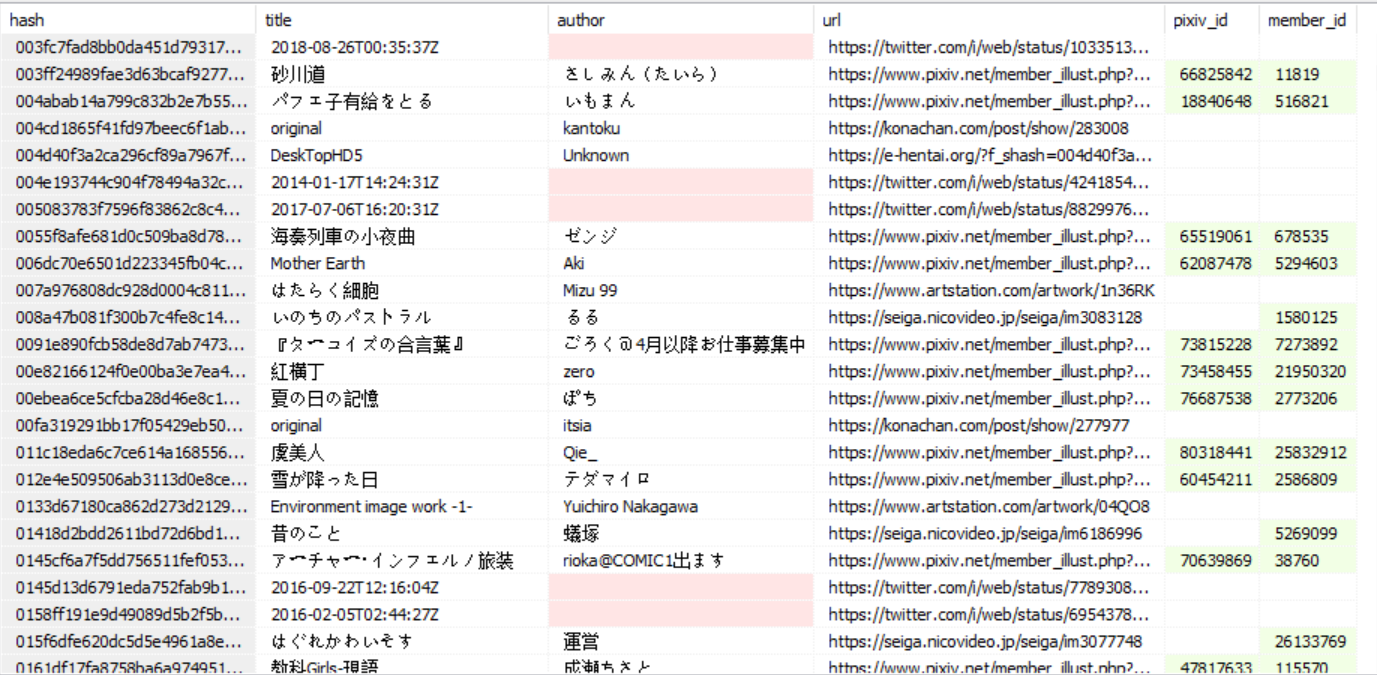
## 改善计划
打算五一的时候写一个GUI界面,左边展示原图(压缩后),右边展示缩略图,确认搜索结果是正确的点个按钮就到下一页,结果不正确的图片就点个按钮,移到另外文件夹内,最后人工搜一遍。
另外很多推特图title是时间,作者没有。可以写个爬虫从推特上找到作者,title就命名为当时推文的内容好了。Read More



 ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
 tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
 ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
 ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.


